Scalably Monitoring Cloud Environments

Keeping track of assets in a cloud environment, whether for security/compliance, historical records, or cost management, is no easy feat. Moving beyond the one-dimensional view of an asset in its current state, we should consider the transformations of an asset over its lifetime, and provide an interface to query this data. The industry standard has been to scan environments on a scheduled interval, and compare assets since the last scan. For larger environments, this can take hours to complete, and is a costly operation. After a scan, the interface to assets provides a snapshot of an inventory instead of a real-time view, and granular historical changes are lost. Cloud providers have some form of an event stream for audit logging, so can we build on this to construct an accurate representation of an asset inventory? Event-based processing is a scalable and cost-effective cloud monitoring solution that avoids the pitfalls of the traditional scanning approach.
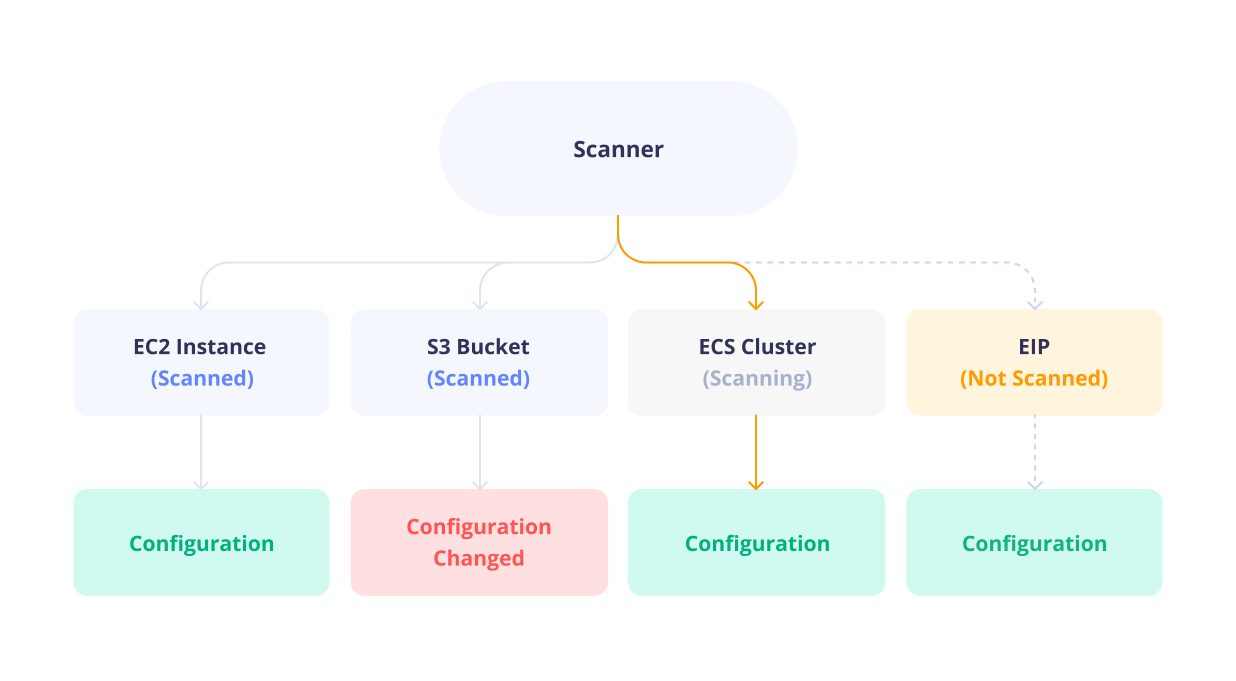
Scanning
Scanning is slow. For every asset in every service, we need to check if it has changed since the last scan. Given large organizations have cloud accounts containing millions of assets, this is just not feasible. Parallelizing the scans can help, but rate limits prevent frequent scans, and the cost of running many scanners is high. Increasing a scan interval from every hour to every day will lead to a less accurate representation of the environment.
A lot can change in one day. A bad actor can modify assets and revert them in minutes. Security checks running on scanned data will be oblivious; the asset looks unchanged.
Outside of security, a real-time view of the environment is still beneficial. A daily scan misses multiple terraform apply runs, or modifications by multiple team members on the same asset.
These risks may not be a problem for small teams, but for large organizations, a straightforward audit trail can function as a source of truth.
Push-based event processing
Scanning is a rudimentary and basic approach to monitoring. It is a pull-based approach, where we ask the cloud provider for the current state of the environment. However, cloud providers already have a mechanism to push events to us. In GCP, the Cloud Asset Inventory API exposes a feed of changes to assets via Pub/Sub. Similarly, we can build on top of AWS CloudTrail to receive real-time events. With such services available, we choose to scale by event volume, not by asset count. However, building a system to handle these events efficiently is not trivial. A successful event-based monitoring system needs to be able to gracefully handle tens of thousands of events per second, and process them in a timely manner.
The OpsHelm approach
OpsHelm leverages both the conventional scanning approach and real-time event processing to provide an accurate view of your cloud environment. If the platform were to rely solely on events, it wouldn’t have any record of pre-existing assets until they were modified, and would miss static assets entirely. Thus, when onboarding to the OpsHelm platform, we perform a full scan of your environment in addition to creating a read-only role that feeds events to our system, with encryption in transit. Scans are performed daily as a safety net, but most if not all changes are captured in real-time.
When an asset is updated, not only does the new configuration get versioned, it attributes the change to the user or service that made it. There is no maximal interval for change to be detected, so we can always provide a granular historical view of each asset in your environment. Since asset configurations are persisted outside of the cloud provider, it’s quick and easy to search through all your environments for assets by their name, tags, asset type, or even the configurations themselves. Within each asset, we can see every change, who made the change, and when. With millions of assets recorded over hundreds of cloud accounts, we can keep our end-to-end processing time within a magnitude of seconds. On every asset change, we run security checks to find any violations, and alert the relevant stakeholders as it happens. The OpsHelm platform naturally extends and complements what cloud providers offer in their respective consoles, and is a powerful tool for security and compliance teams.
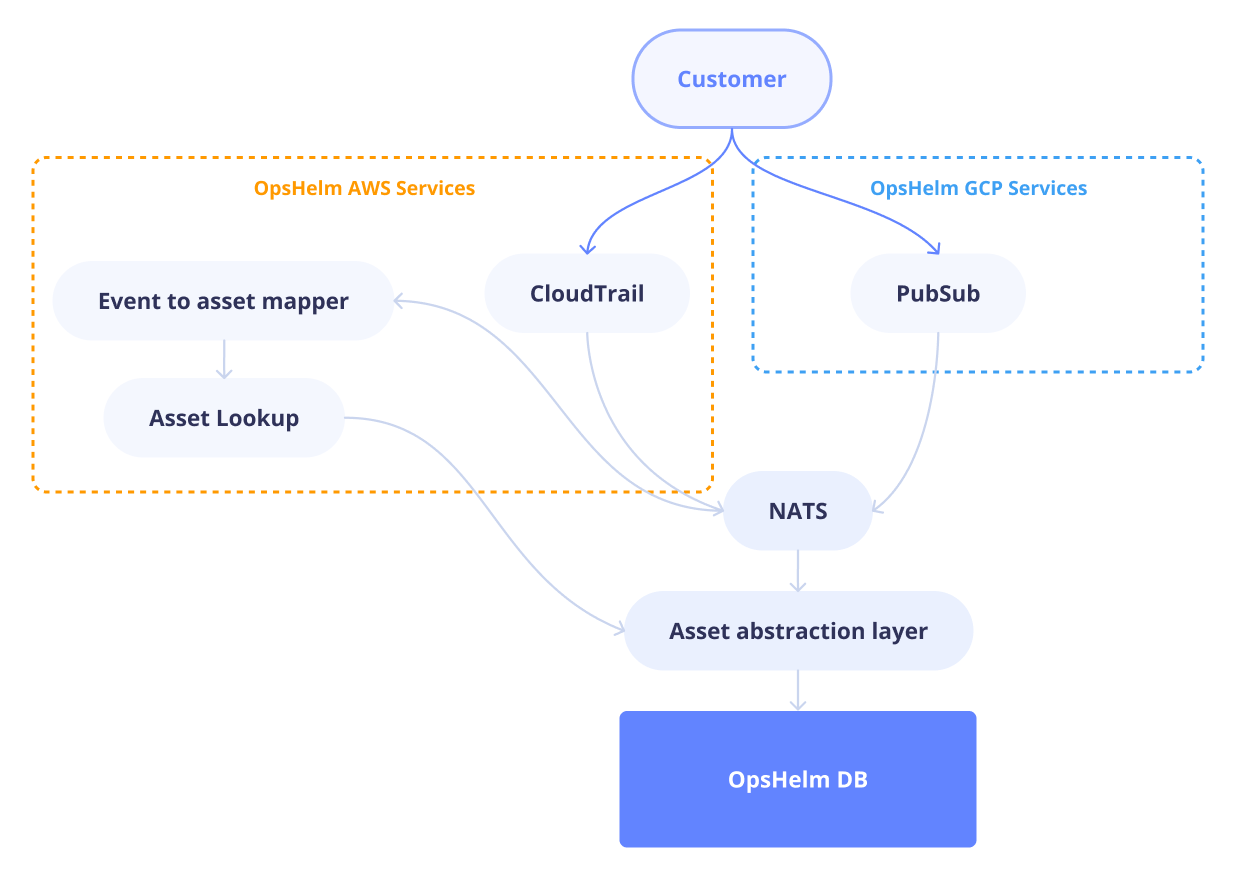
NATS
NATS is a high-performance messaging system that can handle millions of messages per second. With NATS JetStream, an optional persistence layer built on top of NATS, we can improve the at-most-once delivery guarantee to exactly-once, meaning we don’t risk dropping or re-processing any events. This simplifies the event handling process: we ingest messages from the cloud provider, publish them to a NATS queue, and process them in-order. Whereas parallelized scanning scaled linearly with services, event-based processing scales on a much more reasonable metric: the changes themselves. Now, adding more workers means they’ll be directly processing events for asset updates, not looking for assets to process. No compute is wasted inspecting assets that haven’t changed. As the number of events increases during peak times, we can scale up our workers to handle the load, and scale down when the load decreases.
Building on AWS CloudTrail
Although GCP sends the entire asset state in an event, AWS CloudTrail sends limited information, such as the asset ARN and the action performed. How can we tie back these events to the asset state? By using code generation to enumerate all event types for every AWS service, we can map a CloudTrail or EventBridge event to a specific asset and action, such as scaling up an RDS cluster or deleting an S3 bucket. Using events directly sourced from CloudTrail as a core part of the validation, we can ensure that we are successful in extracting its data. Then, parsing out the relevant fields, including what type of modification was applied, we fall back to the AWS SDK to describe the asset and persist the change. Due to the design of this internal workflow, adding support for a service is expedient.
Temporal
Managing the lifetime of an asset from its CloudTrail event, through NATS, into an event parser, and finally into a database, is a complex process. With Temporal, guiding an asset through this journey and ensuring its delivery is straightforward. Temporal abstracts away business logic and tracks an operation’s state in a workflow composed of activities. Every asset trail is easy to follow, while errors are handled gracefully with retries and timeouts, due to the deterministic nature of Temporal workflows. Suddenly, one asset in a sea of thousands jumping between services is traceable and doesn’t risk being lost.
With a systematic approach to event-based processing that ties in scanning, we can build a scalable and cost-effective cloud monitoring solution. The OpsHelm platform is a testament to this, and is a powerful tool for security and compliance teams. By leveraging NATS and Temporal, we can handle millions of events per second and ensure that every asset change is recorded and attributed to the correct user or service. This approach is a significant improvement over the traditional scanning approach, and is a step towards a real-time view of cloud environments.


